
In today’s digital world, data is everywhere. According to the world economic forum, researchers estimated that there are 44 zettabytes of data in the world as of 2020. “Zettabytes” means 21 zeros, so you imagine the amount of data we have!
Social media sites like Twitter, Facebook, Instagram, WhatsApp, and YouTube are the major contributors. Nearly everyone has a smartphone and a profile on one or more of these social platforms.
The total amount of data social media sites, institutions, medical facilities, shopping platforms, automakers, and others generate daily leads to countless comments, discussions, and reviews on different platforms.
These comments and reviews can be either positive or negative, which is called sentiment analysis. On social media platforms, some negative comments and reviews are considered hate speech.
According to the United Nations, hate speech is “speech that attacks a person or group based on attributes such as race, religion, ethnic origin, national origin, sex, disability, sexual orientation, or gender identity.”
Identifying this kind of speech online helps eliminate it and makes everyone feel comfortable and included, no matter who they are. Let’s look at how data science can help achieve this goal.

Obstacles When Identifying Hate Speech
First, we need to look at some of the reasons why identifying hate speech online is difficult. Here are some of the main obstacles data scientists face.
Accurately Classifying Offensive Content is an Ongoing NLP Problem
Identifying sentiments like hate behind textual comments/reviews is a natural language processing problem because detecting offensive content is challenging.
Expressing yourself is a human right, but this freedom can also lead to spreading hate and abuse, especially with the wide use of the Internet and today’s vast online communication. Some social media platforms are trying to implement automated hate speech detection, but this continues to be an ongoing problem. The goal is to use approaches like sentiment analysis and POS tagging to identify this language.
There are also different machine learning algorithms like Logistic Regression, Naive Bayes, and SVM and deep learning algorithms like LSTMs that we can implement to classify offensive content accurately.
Filtering out Hate Speech Proliferated Through Fake Profiles and Bots is Hard
As hard as it is to filter out hate speech from real posts, it’s even harder to filter out this content from fake profiles and bots. It’s difficult for algorithms to identify the boundaries between fake news or comments and human speech, making recognizing hate speech even harder.
Creating fake news is a crime. Companies are working towards removing hate speech and fake hate content using artificial and human intelligence. Social platforms are launching new legal policies to address fake profiles and offensive content.
Recently, Facebook has detected approx 22.5 million hate speech instances on its platform. Facebook is deleting fake accounts and hate content with improved AI bot technology and human content reviewers. Deleting fake accounts and hate content is an important goal for Facebook and other social media profiles.
Basic Approaches for Detecting Hate Speech
Below are some approaches data scientists use to detect hate speech in comments and reviews.

Sentiment Analysis
Sentiment Analysis is a popular technique used to quantify the tone or the emotional strength of a piece of text. Sentiment analysis works by breaking the text down to smaller lexical tokens and comparing each token within a library or a large bank of words that are mapped to their inherent sentiment.
As an example, words like “great,” “amazing,” and “perfect” convey strong positive sentiment, while “horrible” and “pathetic” convey a strong negative sentiment. The algorithm then looks for words in the libraries and calculates a cumulative sentiment score.
Naturally, comments and reviews found online are often complicated. Neutral words, sarcasm, or even slang can make it hard to identify sentiment appropriately. For example, comments like “this neighborhood is sick!” denotes positive sentiment even though the word “sick” doesn’t have positive connotations. Even so, increased negative sentiment can be indicative of hateful/offensive content.

Part-of-Speech Tagging
Part-of-Speech (POS) Tagging is used for essential purposes in NLP. In the POS process, POS tags are assigned to the words in a sentence to indicate what part of speech the word is. These POS tags are NNS for nouns, VB for verbs, ADJ for adjectives, PRP for a pronoun, ADV for adverbs, etc. The use and function of a word in the sentence can be defined using POS tags.
Let’s take a simple example with two sentences, both with the word “watch.”
In the above example, the sentences use the token word (“watch”) in different contexts. In sentence one, “watch” is a noun and in sentence two, “watch” is a verb. Thus, POS tagging helps us understand the context of tokens.
POS tagging makes it easier to detect hate content from an entire text by detecting the tag behind the tokens.
Feature Extraction using Bag of Words
Machine learning algorithms can’t work directly on text data. We need to convert the text into numeric data called vectors. This process is called feature extraction. One of the feature extraction techniques is Bag of Words.
Bag of Words creates a set of all the unique words from the whole text. Each text document is converted into vectors based on the word’s presence and the number of times each word appears in a piece.
We have taken the Twitter hate speech dataset from Kaggle for our analysis.
First, split the data for training and validation using the train_test_split function of the scikit-learn library in Python.
| from sklearn.model_selection import train_test_split
>>(21414,) (21414,) (10548,) (10548,) |
We will get 21414 documents in the training dataset and 10548 in the test dataset.
Now, let’s create a bag of words for both the training and test datasets. For Bag of Words, we are using Count Vectorizer of Scikit-learn in Python.
| from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer() #in scikit-learn |
Output>>
| the number of unique words 32032 Some sample features are:[‘mirror’, ‘mirrors’, ‘mis’, ‘misandry’, ‘misaon’, ‘miscegenation’, ‘misconceptions’, ‘misconstrued’, ‘miserable’, ‘misery’, ‘misinform’, ‘misinformed’, ‘misled’, ‘misogs’, ‘misogynist’, ‘misogynistic’, ‘misogynists’, ‘misogynisttrump’, ‘misogynistâ’, ‘misogyny’,t’, ‘unite’, ‘uniteblue’, ‘united’, ‘unitedinlove’, ‘unitedkingdom’, ‘unitednations’, ‘unitedstates’, ‘unitedstateschampion’, ‘unitedâ’, ‘uniting’, ‘unity’, ‘universal’, ‘universe’, ‘university’, ‘unjust’, ‘unk’, ‘unknown’, ‘unleashed’, ‘unleashes’, ‘unleashyourjoy’, ‘unless’, ‘unlike’, ‘unlikely’, ‘unlimited’, ‘unloads’, ‘unlocked’, ‘unlovable’, ‘unloved’, ‘unlucky’, ‘unlv’, ‘unmasking’, ‘unnecessarily’, ‘unnecessary’, ‘unnie’, ‘unopened’, ‘unopposed’, ‘unpacked’, ‘unpacking’, ‘unpacks’, ‘unpaid’, ‘unpaused’, ‘unplug’, ‘unprecedented’] |
As we see above, Count Vectorizer extracts the features. Now, we can apply machine learning algorithms to these extracted features.
SVM – Machine Learning Algorithm
Linear Support Vector Machines (SVMs) can be used to classify text as offensive or not.
A support vector machine (SVM) is a supervised machine learning model that can classify two-group classification problems. In a text classification problem, SVM will organize the text after being modeled on labeled training data.
Step 1
We are using SGDClassifier for SVM and CalibratedClassifierCV for cross-validation.
| from sklearn import linear_model
from sklearn.calibration import CalibratedClassifierCV sgd =linear_model.SGDClassifier(alpha=0.0001,penalty=‘l2’,max_iter=1000, tol=1e-3) clf.fit(X_train, y_train) #Train model to find best features using SGD Classifier |
Step 2
We have plotted an AUC(Area Under Curve) plot and got 0.9429159362699762 AUC of test data.
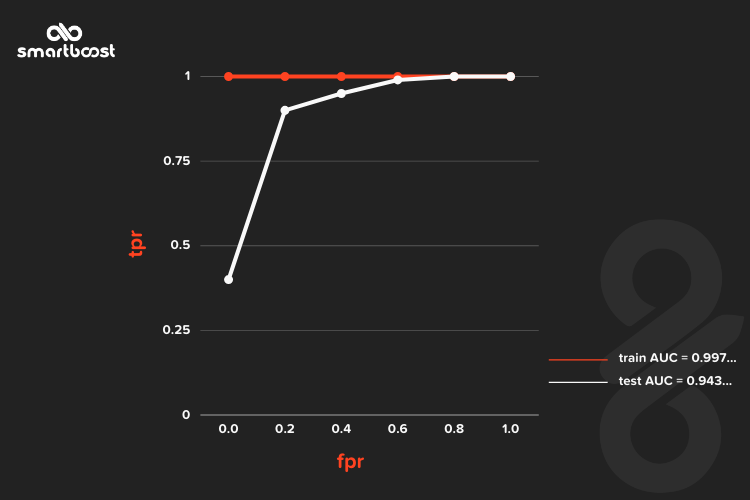
Step 3
A confusion matrix is a performance analysis metric that defines how many values are predicted correctly. We have drawn the confusion matrix of the test data after the SVM modeling, as shown below:

Step 4
Now, let’s see the top 10 features for the positive class label 1 (i.e., hate speech)
| Top 10 features for positive class with class label 1
2.155611873343245 allahsoil |
We can see from the above output that the top features are quite relevant to hate. For the complete code, refer here.
Step 5
Next, let’s predict a new/unseen comment:
| Y = count_vect.transform([‘at work: attorneys for white officer who shot #philandocastile remove black judge from presiding ov…’]) print(clf_BOW_lr.predict(Y)) >>[1] # means it’s hateful/offensive content |
As we can see from the above code, the SVM classifier correctly classifies the text as hate/offensive content.
BERT
Google’s BERT (Bidirectional Encoder Representations from Transformers) launched in 2019 and consists of state-of-the-art NLP techniques. These strategies better understand the words’ context within a sentence to make more accurate classifications regarding hate speech.
BERT was pre-trained on Wikipedia (approx 2500 million words) and many books (800 million words) and only required fine-tuning with just one additional output layer to create state-of-the-art models.
BERT’s model architecture is a multi-layer bidirectional Transformer encoder stacked up together. BERT is a bi-directional model because its self-attention layer performs self-attention in both directions. It learns information from both the left-to-right and right-to-left side of a token (word)’s context during training.
Let’s take a simple example:

In this example, “orange” is the token word. “Orange” can be a fruit or a color. Based on the context like “eat,” we classify it as a fruit, and based on the “dress” context, we classify it as a color.
We need to understand the context of the words from both directions. Without considering context, it’s impossible for machines to truly understand the meaning of words.
BERT has two stages: pre-training and fine-tuning. Pre-training is relatively expensive and can take up to four days on 4 to 16 Cloud TPUs. The best approach is to download the pre-trained BERT model and do fine-tuning as needed. There are different pre-trained BERT model variants available here.
The Importance of BERT in Marketing
Now in the era of digital marketing, Google’s BERT is a boom to the companies. BERT helps companies create high-value content and build their brand. Here are some other ways BERT is essential to marketers:
- BERT improves how Google understands and analyzes search queries. With BERT, Google rewards relevant content.
- BERT interprets the appropriate meaning of a word by looking at the words that come before and after. This leads to a better understanding of queries.
- BERT understands what words in a sentence are useful and searches for information according to that context.
- Every user is looking for the most direct and relevant answer. With BERT’s laser-focused answers, this is possible.
- With BERT, high-quality content created with the user in mind will outrank lengthy, low-quality content.
Conclusion
Hate speech continues to be a problem as more and more people use social media. With this increase, we need advanced, accurate systems that can detect this content.
We can use some algorithms to detect hate speech in comments and reviews, and technology is only getting better. Hopefully, in the near future, we can eliminate hate speech on the web for good!